
조건:
- 1 <= nums1.length <= nums2.length <= 1000
- 0 <= nums1[i], nums2[i] <= 10^4
- All integers in nums1 and nums2 are unique. (배열 안의 정수 값은 중복이 존재하지 않는다)
- All the integers of nums1 also appear in nums2.
권장 사항: Could you find an O(nums1.length + nums2.length) solution?
의역: 두 개의 정수 배열 nums2[]와 nums2[]의 부분집합 nums1[]이 주어질 때
ex: nums2 = {1,2,3,4,5,6}, nums1 = {1,5}
정수형 배열 ans[]를 반환하라 (nums1.length == ans.length)
ans[]의 각 인덱스값은 nums1[]의 각 인덱스 값과 매칭되어 ans[i] = function(nums[i]);
nums1의 각 인덱스의 해당하는 값을 nums2에서 찾고 그 뒤로 해당 값보다 큰 값이 나오면 그 값을 ans에 집어 넣는다.
만약 nums2에 뒤에 더 큰 값이 나오지 않는다면 -1을 넣는다.

의역: nums1[0]의 값은 nums2[2]의 값과 매칭되며 nums2 배열에서 다음 인덱스 안에 4보다 큰 값이 없으므로 ans[0] = -1
nums[1]의 값은 nums2[0]의 값과 매칭되며 nums2 배열에서 다음 인덱스 값이 1보다 큰 3이므로 ans[1] = 3
nums[2]의 값은 nums2[3]의 값과 매칭되며 nums2 배열에서 3 다음 인덱스가 존재 하지 않으므로 ans[2] = -1

의역: nums1[0]의 값은 nums2[1]의 값과 매칭되며 nums2 배열에서 다음 인덱스 값이 2보다 큰 3이므로 ans[0] = 3
nums[1]의 값은 nums2[3]의 값과 매칭되며 nums2 배열에서 3 다음 인덱스가 존재 하지 않으므로 ans[1] = -1
풀이:
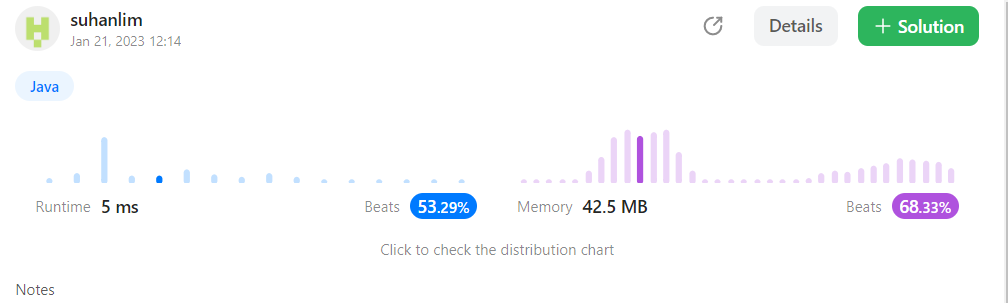
1. 정공법 브루트 포스
class Solution {
// 시간 복잡도 O(n*m) 공간 복잡도 O(n)
public int[] nextGreaterElement(int[] nums1, int[] nums2) {
int ans[] = new int[nums1.length];
Arrays.fill(ans,-1);
for(int i=0;i< nums1.length;i++){
int pos = -1;
for(int j=0;j< nums2.length;j++){
if(nums1[i]==nums2[j])
pos = j;
if(pos!=-1&&nums2[pos]<nums2[j]){
ans[i] = nums2[j];
break;
}
}
}
return ans;
}
}
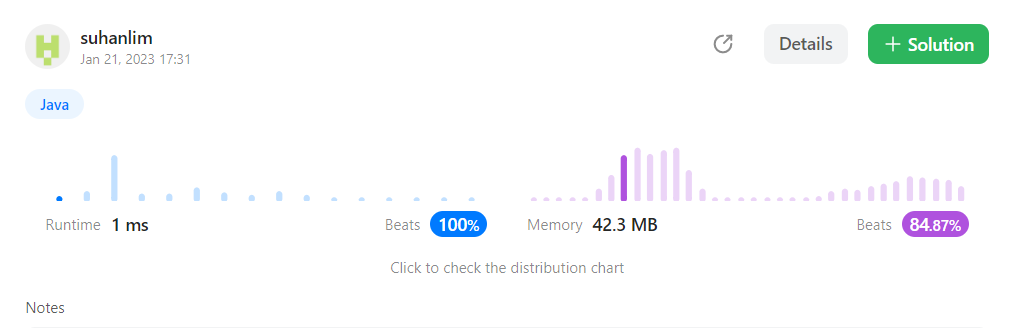
2. 기수 정렬 응용 (정수형의 범위 만큼의 저장공간 생성 후 활용)
class Solution {
// 시간 복잡도 O(n+m) 공간 복잡도 O(n)
// 가능한 이유 nums1[i], nums2[i] 값의 범위가 좁기 때문에
public int[] nextGreaterElement(int[] nums1, int[] nums2) {
// 0 <= nums1[i], nums2[i] <= 10^4
int numsNextBigger[] = new int[10001];
Arrays.fill(numsNextBigger,-1);
int ans[] = new int[nums1.length];
// numsBigerNext에 nums2의 모든 값에 대한 다음 큰 값의 정보를 담는다.
for(int i=0;i<nums2.length;i++){
for(int j=i;j<nums2.length;j++){
if(nums2[i]<nums2[j]){
numsNextBigger[nums2[i]] = nums2[j];
break;
}
}
}
// 반복문을 통한 저장된 자료값 매핑
for(int i=0;i<nums1.length;i++){
ans[i] = numsNextBigger[nums1[i]];
}
return ans;
}
}
3. monotone stack기법 변형
(스택의 원소들을 오름차순, 혹은 내림차순 상태를 유지하도록 하는 것)
스택에 숫자 x를 넣는다고 할 때 x를 넣기 전에 x 이상의 수를 모두 제거하고 x를 넣는 것.
class Solution {
// 시간 복잡도 O(n) 공간 복잡도 O(n)
public int[] nextGreaterElement(int[] nums1, int[] nums2) {
int ans[] = new int[nums1.length];
Stack<Integer> stack = new Stack<Integer>();
HashMap<Integer,Integer> map = new HashMap<Integer,Integer>();
// nums2의 모든 값들의 nextGreaterElement 정보를 map에 저장
for(int i=0;i<nums2.length;i++){
int tmp = nums2[i];
// stack에 순서대로 값을 push 하다가 다음 값이 전에 push 한 값보다 크다면
while(!stack.isEmpty()&&tmp>stack.peek()) {
// 전에 넣어둔 값을 제거 하고 전에 넣어둔 값의 nextGreaterElement로 map에 저장
map.put(stack.pop(), tmp);
// while문으로 반복하게 되어 차례대로 과정 수행
}
stack.push(tmp);
}
int i=0;
for (int num:nums1) {
// getOrDefault() 함수는 찾는 key 값이 없다면 정해둔 (-1)값을 반환
ans[i++] = map.getOrDefault(num,-1);
}
return ans;
}
}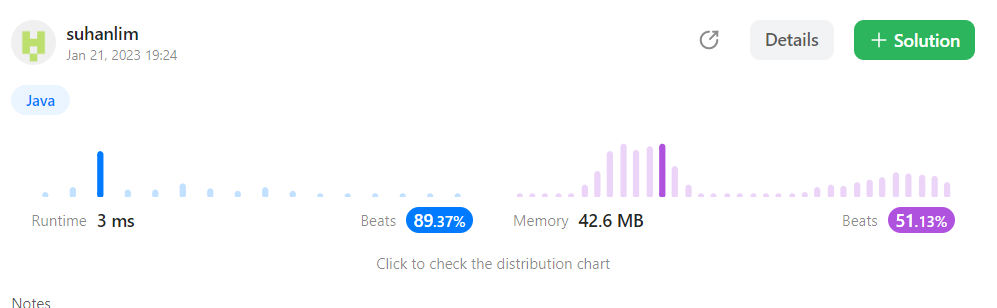
메모: 컬렉션의 빌트인 함수들을 사용하여 빅오 표시법의 시간복잡도를 줄여도 해당 빌트인 함수들의 소요 시간으로 인해 분명히 단순 빅오 표기법 상으로는 3번 풀이가 더 효율적이나 예상외로 2번이 더 효율적이었다.
되도록이면 빌트인 함수들을 사용하는 걸 줄이자.
'PS > Easy' 카테고리의 다른 글
| 501. Find Mode in Binary Search Tree (해석 + 풀이) (0) | 2023.01.25 |
|---|---|
| 500. Keyboard Row (해석 + 풀이) (0) | 2023.01.23 |
| 495. Teemo Attacking (해석 + 풀이) (0) | 2023.01.19 |
| 492. Construct the Rectangle (풀이 + 해석) (0) | 2023.01.15 |
| 482. License Key Formatting (해석 + 풀이) (0) | 2023.01.13 |