1. MySQL 다운로드 설치
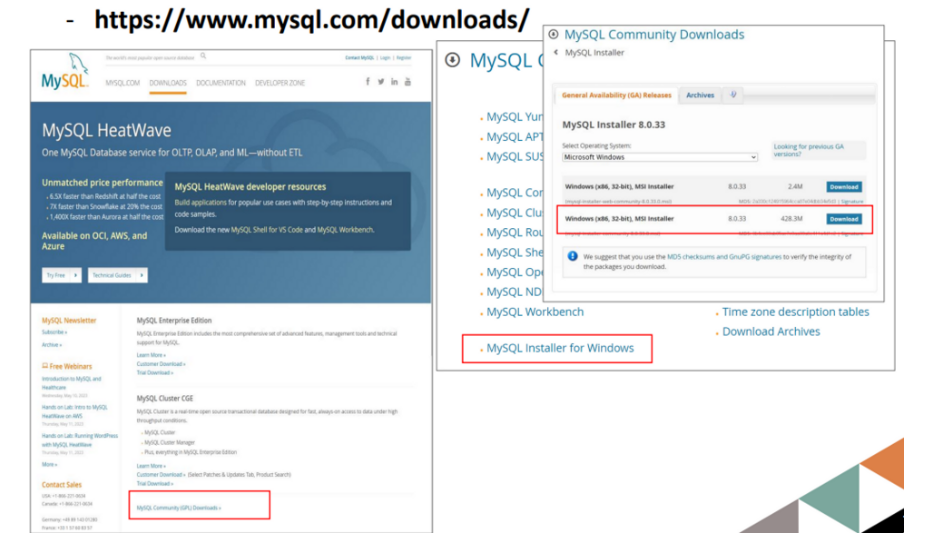


중요!: 여기서 설정해둔 비밀번호는 따로 메모해두거나 꼭 암기해 두어야 한다.
2. MySQL Workbench 실행 후 연결 객체 생성
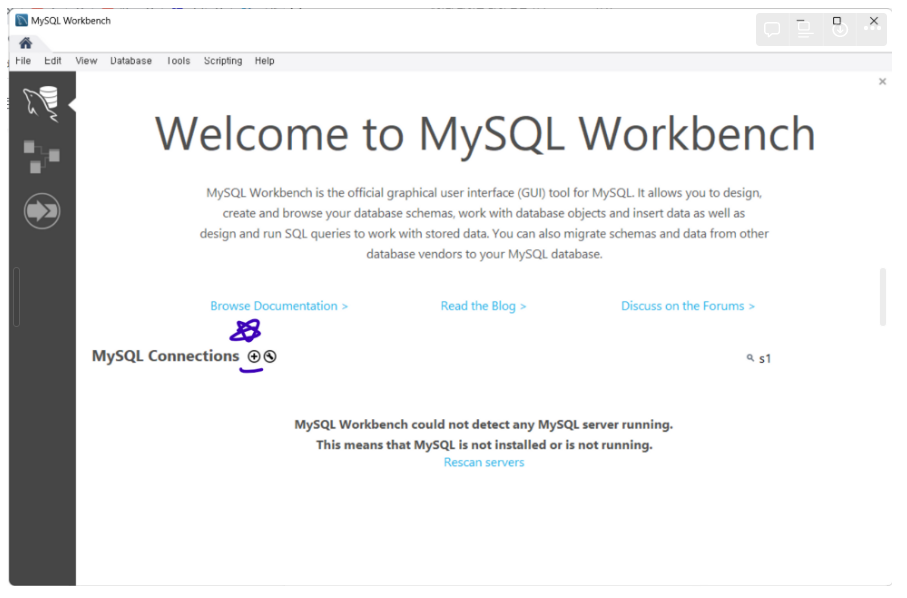
+버튼을 통해 새 연결 객체 생성

여기서 Username과 설정한 Password를 SpringBoot에서 연결 작업에 필요하기 때문에 따로 메모해두거나 꼭 암기해 두어야 한다.
Test Connection 버튼을 통해 연결이 잘 되는지 확인!

Ok 버튼을 통해 생성

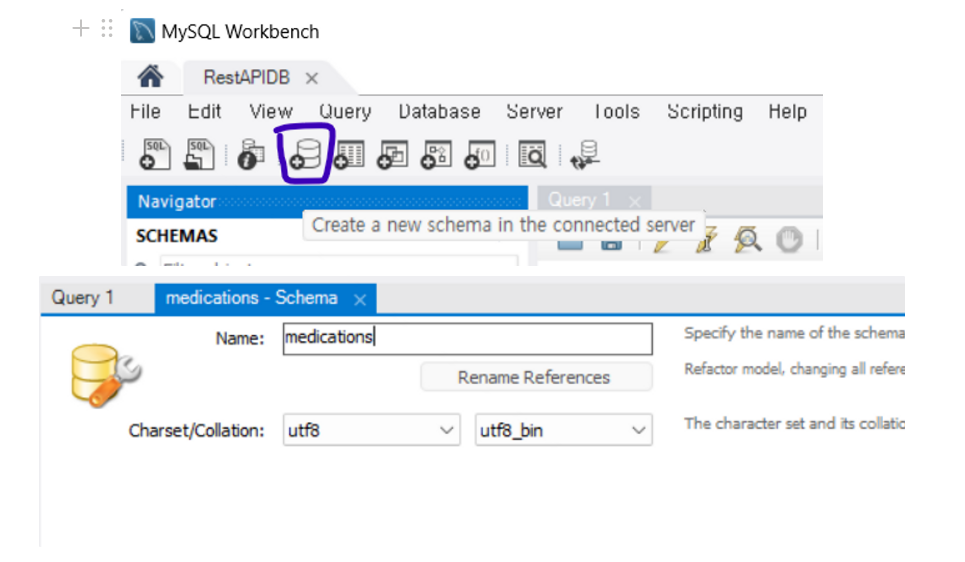
3. 사용할 DB Schema 생성
'CS > DataBase' 카테고리의 다른 글
| 오라클에서의 트랜잭션 (0) | 2023.06.05 |
|---|---|
| 장애와 복구 (0) | 2023.05.31 |
| 직렬 가능한 스케줄이 되도록 하는 방법 (0) | 2023.05.31 |
| 동시성 제어 (0) | 2023.05.22 |
| 트랜잭션 (0) | 2023.05.19 |




