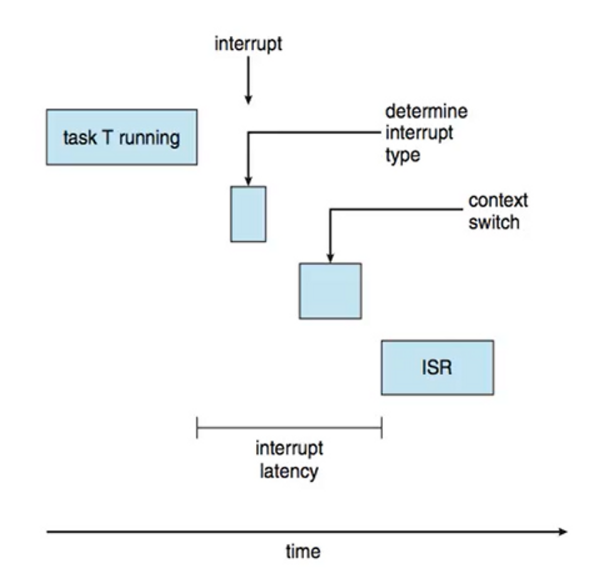
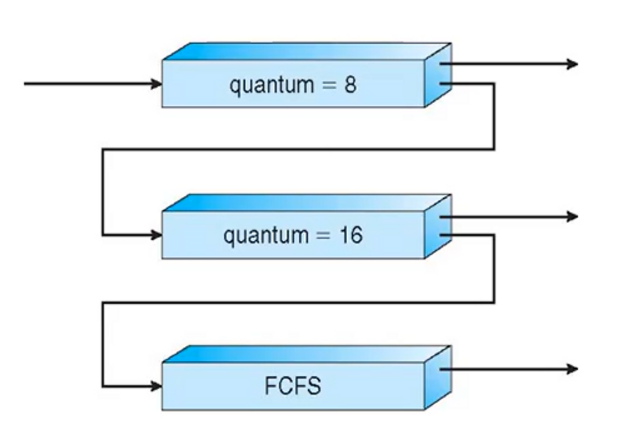
내부 단편화
- 할당된 메모리 블록이 실제로 사용되는 데이터보다 크기 때문에 낭비 공간이 생기는 문제
- 페이지 프레임의 크기를 줄이면 내부 단편화는 덜 될지 몰라도 페이지의 갯수가 늘어나기 때문에 페이지 테이블의 크기는 커진다.
- 메모리와 CPU 부담 증가
페이지 테이블
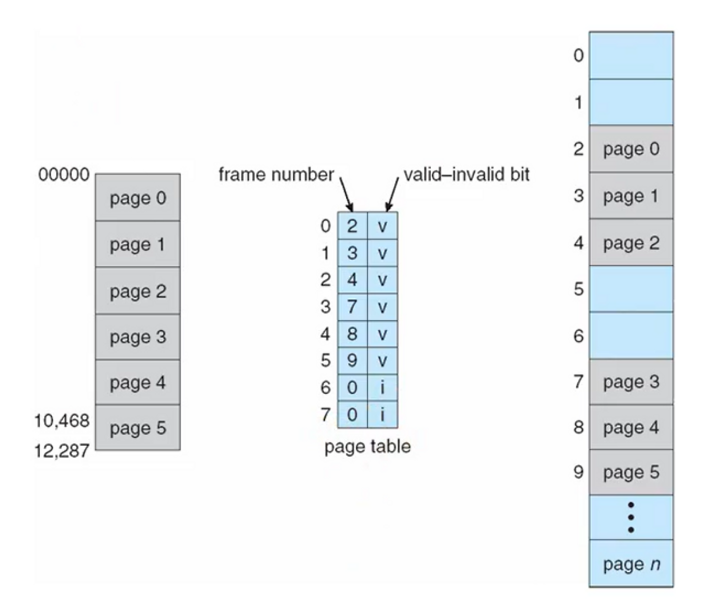
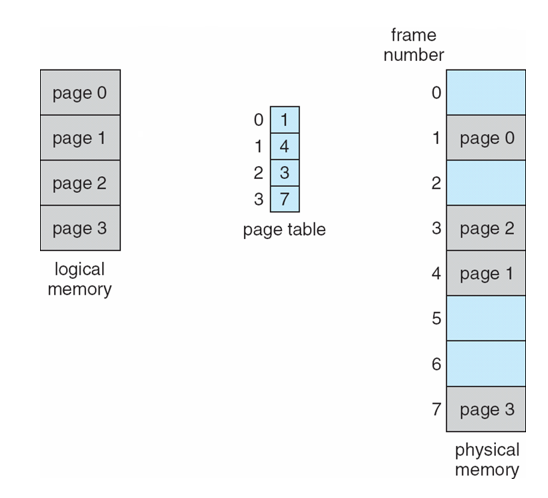
- 가상 메모리 공간(페이지)와 물리 메모리 공간(페이지)의 대응 정보를 저장하는 데이터 구조
- 프레임 번호(Frame Number): 해당 가상 페이지가 매핑된 물리적 페이지 프레임의 번호
- 프레젠트 또는 벨리드 비트(Present or Valid Bit): 해당 가상 페이지가 현재 메모리에 로드되어 있는지(즉, "프레젠트") 또는 유효한지(즉, "벨리드")를 표시하는 비트 값
- 프로텍션 비트(Protection Bits): 해당 페이지에 대한 접근 권한을 표시하는 비트 값
- 수정 비트(Modified Bit): 해당 페이지가 프로세스에 의해 수정되었는지를 나타내는 비트 값
- 참조 비트(Referenced Bit): 해당 페이지가 최근에 접근되었는지를 나타내는 비트 값
- 데이터 저장 작업 수행시 활용되는 레지스터들
- PTBR(Page-table base register): 현재 실행 중인 프로세스의 페이지 테이블의 시작 위치를 가리키는 포인터를 저장하는 레지스터
- 활용: 가상 주소를 물리 주소로 변환하는 작업을 수행
- PTLR(Page-table length register): 메모리 관리를 위해 현재 실행 중인 프로세스의 페이지 테이블의 길이를 저장하는 레지스터
- 활용: 주소 변환 시 참조하려는 가상 주소가 유효한 범위 내에 있는지 확인하는 작업을 수행
- PTBR(Page-table base register): 현재 실행 중인 프로세스의 페이지 테이블의 시작 위치를 가리키는 포인터를 저장하는 레지스터
- 모든 데이터/명령 접근은 2번의 메모리 접근이 필요
- (가상 주소가 매핑된 물리적 주소 찾기)페이지 테이블 접근 1번
- (찾아낸 물리적 메모리 주소에서 실제 데이터 또는 명령 가지고 오기)데이터/명령 접근 1번
- 특별한 빠른 검색 하드웨어 캐시(연관 메모리, TLBs)로 해당 문제 해결 가능
TLB(Translation Lookaside Buffer)
- 매우 빠른 접근 시간을 갖는 캐시로, 최근에 사용된 페이지 주소 변환을 저장 이후 CPU가 가상 주소를 참조할때 먼저 TLB를 확인하여 해당 정보를 가지고 있다면 가상 주소를 통해 물리적 주소를 알아낼 필요없이 단번에 물리적 주소에 접근 할 수 있게 된다.
- 페이지 테이블의 일부를 캐시하여 CPU의 메모리 접근 속도를 향상시키는 도구
페이지 테이블 종류
- 단일 레벨 페이지 테이블 (Single-Level Page Table): 가장 기본적인 형태의 페이지 테이블로, 각 가상 페이지에 대해 한 개의 페이지 테이블 항목이 존재
- 다단계 페이지 테이블 (Multi-Level Page Table): 페이지 테이블이 여러 단계로 나뉘어 있어서, 대용량 메모리를 관리하는 데 더 효율적 각 단계에서 부분적인 가상 주소가 인덱스로 사용되어 다음 단계의 테이블에 대한 참조를 제공한다. 즉 여러 단계를 거쳐서 물리 메모리 주소에 접근하는 페이지 테이
- 역페이지 테이블 (Inverted Page Table): 각 물리 메모리 페이지에 대한 엔트리를 하나만 가짐으로써 전통적인 페이지 테이블보다 테이블의 크기가 작은 테이블을 구성
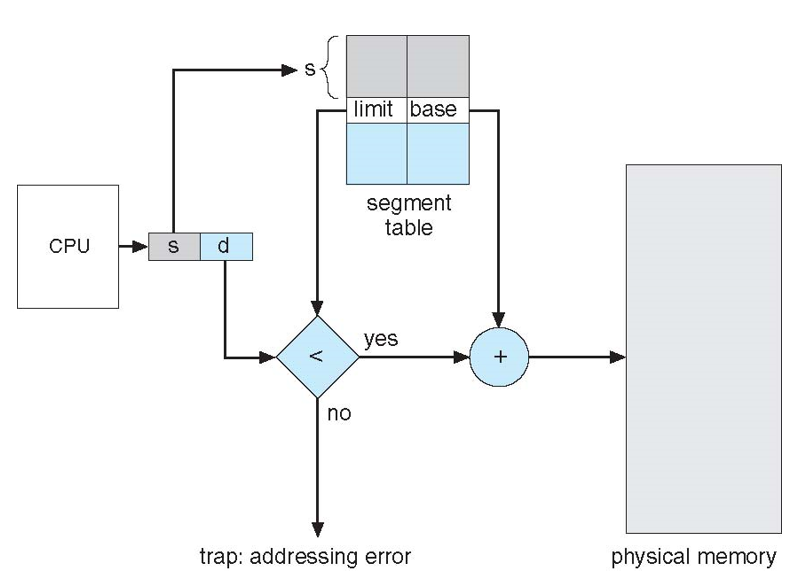
- 세그먼테이션 테이블 (Segmentation Table): 가상 메모리를 여러 세그먼트로 나누는 메모리 관리 기법 각 세그먼트는 다양한 크기를 가질 수 있으며, 일반적으로 코드, 데이터, 스택 등의 다른 유형의 정보를 구분하는 데 사용
- 해시된 페이지 테이블 (Hashed Page Table): 이 구현 방법은 역페이지 테이블과 비슷하며, 주로 대용량 주소 공간을 관리하기 위해 사용 해시된 페이지 테이블은 가상 페이지 번호를 해싱하여 페이지 테이블 항목을 찾는다.